IBM平台计算公司的Rohit Valia,利用一天时间填补了我对一些优秀的技术计算和使用IBM平台的Symphony和LSF产品生成的大数据基准测试结果的空白。 这些结果给人留下了深刻的印象。
·Terasort基准运行速度比使用BigInsights 1.3.0.1和Symphony 5.2快40倍。
·一个使用Symphony5.2的MapReduce测试比仅仅使用Apache的MapReduce的类似配置运行速度快63倍。
·Berkley SWIM 使用与Symphony结合的Hadoop1.0.1的测试运行速度比使用Hadoop1.0.1的测试快6倍。
快照技术分析
当人们向我展示他们的基准结果时,我通常想起了一个引用,“有三种谎言:谎言、该死的谎言和统计数据。”往往要归因于Benjamin Disraeli或Mark Twain。据作者对他们的了解,基准肯定会被添加到列表中。
不管谁真正应该对这句话负责,供应商往往是使用和滥用基准,希望赢得潜在的客户,即使在基准很少或没有做客户建议使用的系统。 供应商为什么这样做呢? 这是因为直到在现实生活中安装和使用具体的工作负荷,不然很难提前知道集群或网格计算解决方案事实上如何执行。
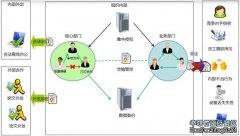
由于供应商不负责提供复杂的,昂贵的计算解决方案,提供业务,他们试图证明可以在一个特定的配置上做有点类似的负载。IBM引用的基准设计主要是为了显示某些集群或网格为基础的计算解决方案的类型将如何执行。
客户运行自己的应用程序时能否看到相同或相似的性能是一个关键问题。答案视情况而定,运行在非常类似的系统配置上的非常相似的工作负载可能会有非常相似的性能,这些配置是由具有非常相似的专业知识的IBM员工设置的。 工作负荷上运行的配置有很大的不同,且由不同专业水平的的人员配置,所以性能也不一样。
吸引我注意的是当把IBM Symphony或LSF插入到某种特定的环境时,性能的巨大改进,在这种环境下,被测试的软件和系统配置是相同的。 虽然我对结果并不是非常惊讶,因为我已经在平台计算公司工作了近二十年,只是结果给人留下了深刻的印象。
IBM正试图使用可以管理数以千计系统的努力的智能编排工具,目的是在性能上可以有很大的不同,基准测试结果可以很好的支持提高效率和降低成本。我感到好奇的是,通过使用其他的编排软件是否可以产生类似的结果,如著名的Beowulf项目。由于这种类型的配置还没有进行测试,我们不知道这个问题的答案。
如果您的组织参与技术计算,高性能计算或大数据,观察IBM的做法,更多地了解如何提高您操作的性能和效率将是非常明智的。 此外,你很可能会发现,当低延时的编排工具(如Symphony)正优化资源的使用时,你可以使用一个更小的系统配置来完成同样的事情。

本节将说明将SAN技术用于备份的三种方法,以及它们在解决网络备份常见问题时的效率。 第...
固态硬盘是近1-2年内发展起来的,从最先应用到上网本硬盘到如今的固态移动硬盘。固态硬盘...
近日笔者昨天接到IBM老款硬盘,硬盘开机有吱吱的规律异响,有时能认到盘,也有可能不认。...
杭州某报业集团西数笔记本硬盘数据恢复成功。该集团的一台电脑无法正常启动系统,无法识...
爱国者移动存储王拆解,供大家了解欣赏。
12月7日消息,据国外媒体报道,硬盘巨头希捷和西部数据正在竭尽全力摆脱因泰国洪水造成的...
“南有华强北,北有中关村”,中国两个最大规模的IT聚散地,遍地都是数据恢复公司,少说...
 沈阳数据恢复
沈阳数据恢复